
When it comes to handling real-time data streams with scalability and fault tolerance, Apache Kafka has established itself as a go-to solution for developers and organizations worldwide. Originally developed by LinkedIn and now an open-source project maintained by the Apache Software Foundation, Kafka is more than just a messaging system—it's a robust, distributed event-streaming platform.
What is Apache Kafka?
Apache Kafka is a distributed event-streaming platform designed to handle real-time data feeds. It allows developers to build applications that can produce, process, store, and consume streams of data efficiently.
Key features include:
- High Throughput: Handles millions of messages per second.
- Scalability: Distributes data across multiple brokers for load balancing.
- Fault Tolerance: Ensures no single point of failure through data replication.
- Durable Storage: Persists data for configurable durations.
Core Components of Kafka
1. Producers
Producers are services or applications that generate and send data to Kafka topics. For example, a web server sending user activity logs.
2. Consumers
Consumers subscribe to Kafka topics to read and process data. They can operate individually or as part of a consumer group for parallel processing.
3. Topics
Topics are the central abstraction in Kafka where data is stored. Each topic can have one or more partitions that divide the data for scalability.
4. Partitions
Partitions enable Kafka to distribute data across brokers. Each partition is ordered and replicated for durability.
5. Brokers
Kafka brokers are servers that store data, manage partitions, and handle client requests. They work together as part of a Kafka cluster.
6. ZooKeeper/KRaft
Previously, Kafka used ZooKeeper for cluster management and metadata storage. With newer versions, Kafka has introduced KRaft (Kafka Raft) as an integrated metadata manager.
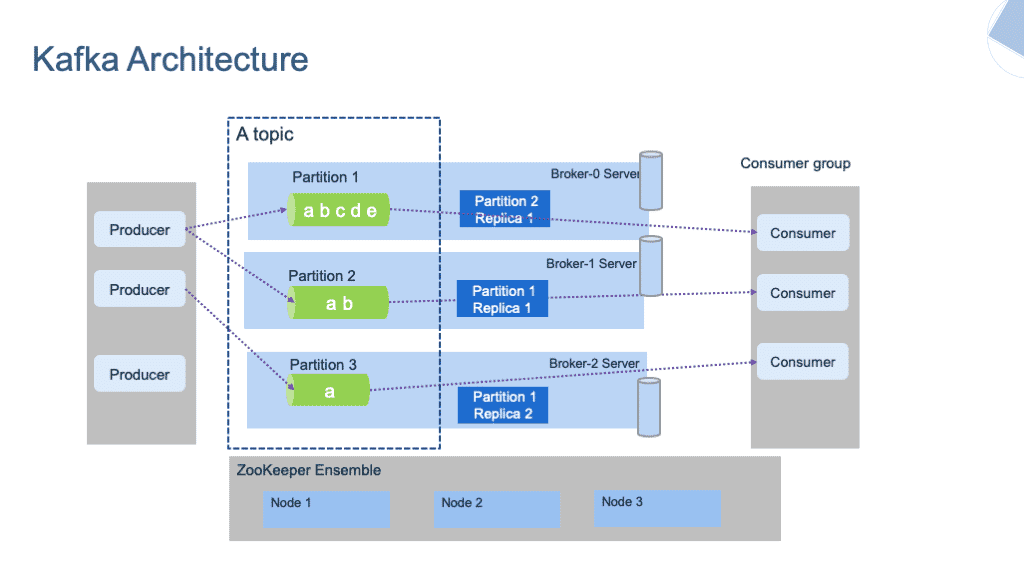
How Kafka Works
- Producing Data: Producers send messages to a specific topic in the Kafka cluster.
- Storing Data: Messages are stored in partitions on brokers and replicated for fault tolerance.
- Consuming Data: Consumers read messages from topics, either from the latest message or from a specific offset.
- Stream Processing: Frameworks like Apache Flink or Kafka Streams process data in real-time.
Key Use Cases
- Real-Time Analytics: Process data streams from IoT devices, social media platforms, or financial markets.
- Event Sourcing: Capture changes in a system’s state as an event log.
- Log Aggregation: Centralize logs from distributed systems for monitoring.
- Data Pipelines: Move data between systems such as databases, cloud storage, and applications.
- Metrics and Monitoring: Collect and analyze performance metrics in real-time.
Advantages of Kafka
- Scalability: Kafka’s distributed architecture allows horizontal scaling by adding more brokers.
- Fault Tolerance: Data replication ensures high availability and durability.
- Flexibility: Kafka is suitable for both batch and real-time stream processing.
- Ecosystem Integration: Supports integration with popular tools like Hadoop, Spark, Elasticsearch, and more.
Challenges and Considerations
- Complexity: Setting up and managing a Kafka cluster requires expertise.
- Data Consistency: Managing consistency in distributed systems can be challenging.
- Resource Intensive: Kafka demands significant memory and disk resources for high throughput.
Getting Started
Ready to explore Kafka? Here are some steps to get started:
- Install Kafka: Download the binaries from the official website and follow the setup guide.
- Understand Topics and Partitions: Experiment with creating and managing topics.
- Write a Producer and Consumer: Use libraries like Kafka Client for Java, Python, or Node.js.
- Explore Kafka Streams: Dive into real-time stream processing with Kafka Streams or other compatible frameworks.
Apache Kafka is not just a tool; it’s a powerful ecosystem that has redefined how we handle data streams. From event sourcing to building scalable, real-time systems, Kafka offers the tools you need to tackle modern challenges in data engineering. Start small, and scale big—that’s the Kafka way!